

Bereits lange bevor das Internet in der heutigen Form auch nur ansatzweise geplant wurde, machte man sich Gedanken, wie denn Computernetzwerke konzipiert sein müssten, um möglichst ausfallssicher zu sein. Das wird verständlich, wenn man bedenkt, dass die technischen Grundlagen für unser heutiges Internet in der Zeit des „Kalten Krieges“ geplant worden waren. Maßgeblich vorangetrieben wurden diese Überlegungen mittels Forschungen der Rand Conporation ab den frühen 1960er Jahren. Die Rand Corporation war nach dem zweiten Weltkrieg als Think Tank gegründet worden um im militärischen Bereich zu forschen und zu beraten. Diese Beratungen betrafen um die Mitte des 20. Jahrhunderts vor allem Aspekte zur Zeit des Koreakrieges (1950 – 1953) und des bereits erwähnten „Kalten Krieges“. Die eher propagandistische Auseinandersetzung der USA und der damaligen Sowjetunion gipfelte in der sogenannten Kubakrise (1962). Der Welt wurde damals bewusst, dass im schlimmsten Fall sogar mit einer atomaren Auseinandersetzung zu rechnen war.
In diesen Jahren lief die (militärische) Kommunikation vornehmlich über Telefonleitungen und Kurzwellenfunk. Beide Anwendungen waren aus strategische Sicht sehr leicht verwundbar. Mit dem Aufkommen der Verbindung von Computern mittels netzwerkartiger Verbindungen war es naheliegend, sich über die Art und Weise der Verbindungen im Hinblick auf die größtmögliche Sicherheit Gedanken zu machen. Maßgeblich beteiligt in dieser Forschung war der Informatiker Paul Baran, der im Computer Science and Mathematics Department der Rand Corporation beschäftigt war. Mit seiner Arbeit „On Distributed Communication“ 1964 und der dazu geleisteten Forschung legte er die Basis für grundlegende Aspekte des heutigen Internets. Er stellte dabei Überlegungen bezüglich Netzwerktypen an, die mit dem folgenden Schaubild dargestellt werden können:
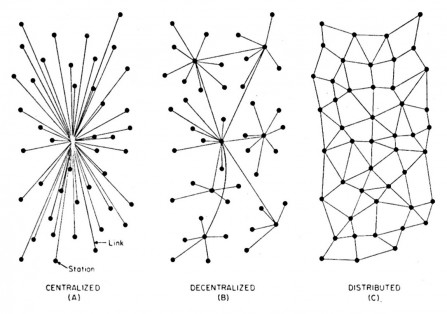 Wir sehen hier links ein zentrale Netzwerk, das bei einem Angriff auf den zentralen Knoten soft ausfallen würde
Wir sehen hier links ein zentrale Netzwerk, das bei einem Angriff auf den zentralen Knoten soft ausfallen würde
in der Mitte ein dezentrales Netzwerk, das auch nicht als besonders sicher anzusehen ist.
Paul Baran empfahl daher das distribuierte Netzwerk als die Variante mit der größten Ausfallsicherheit.
Zusätzlich zu den distribuierten (=verteilten) Verbindungen innerhalb des Netzwerk sollten auch die Daten in einzelnen Paketen über unterschiedliche Wege kommuniziert und schließlich beim Empfänger wieder zusammengesetzt werden.
Diesen drei Netzwerktypen gemeinsam ist die Art und Weise der Zuordnung von Links zu Knoten. Damit zählenn diese Netzvarianten zu den Netzen, in denen die Zuordnung der Links zu Knoten mit Hilfe einer Bell Kurve dargestellt werden können. Diese Verteilung wird als Skalenverteilung bezeichnet. Im Gegensatz dazu gibt es sogenannte skalenfreie Netze, bei denen die Verteilung von Links und Knoten nur mittels exponetieller Kurven dargestellt werden können – dadurch sind die Wertigkeiten von enormen Unterschieden geprägt (dazu mehr bei der Beschreibung der skalenfreien Netzwerke) .
Mit der Weiterentwicklung des Internets ist auf einer ähnlich verteilten Netzwerkstruktur ein System (= Ebenen = Layer) von Datenflüssen (=Kommunikationswegen) entstanden, das an die in den 1970er Jahren vorherrschende Systemarchitektur von Computern erinnert. Damals hatte man in Rechenzentren einen zentralen Rechner, an den eine Anzahl von Terminals angeschlossen war. Die Rechenaufgabe oblag dem zentralen Rechner (Mainframe) – die Terminals waren reine Eingabegeräte. Das Internet selbst ist heute ein komplexes Netzwerk von Servern – meist ganzen Serverfarmen, an die im Bedarfsfall alle möglichen Geräte – von Smartphones, Tablets, PersonalComputern, IoT – Geräten Daten liefern oder Daten abfragen. Damit haben sich auf der technischen Basis von distribierten Netzwerken mehrere Ebenen von kommunikativen skalenfreien Netzwerken entwickelt. Dies hat zu einer extrem ungleichen Wertigkeit einzelner Knoten geführt, was damit einher geht, dass die sogenannten Hubs über unglaubliche Mengen von Daten verfügen. Dies führt zu einem dominanten Geschäftsmodell, das in vielerlei Üerwachungsphantasien mündet – (Surveillance Capitalism – Shoshana Zuboff)
Eine gegenteilige Entwicklung gibt es mit der Entwicklung der Blockchain. Einer Technologie, die auf Verteilung von verschlüsselten Daten und Rechnerkapazitäten auf annähernd gleichwertige Knoten setzt. Eine Blockchain kann als Datenbanksystem gesehen werden, in dem Informationen dezentral auf vielen Rechnern fälschungssicher abgelegt werden. Diese Datenbank kann als verteiltes Register – oder Hauptbuch (Distributed Ledger) wie bei Buchhaltung üblich, bezeichnet. Sie ist einem Peer-to-Peer-Netzwerk abgelegt. Auf jedem Rechner liegt eine vollständige Kopie der Blockchain. In der Folge werden alle Transaktionen und Datenbewegungen auf allen Knoten des Netzwerks abgelegt. Die Problematik dabei ist die beschränkte Anzahl von Transaktionen pro Zeiteinheit.
Es gibt weitere Entwicklungen, die dieses Prinzip adaptieren und die Daten nicht auf allen sondern auf einer bestimmten Anzahl von Knoten ablegen und auch mittels Verschlüsselung sicher machen wollen. Die Entwickler von Holochain wollen die Dominanz der zentralisierten Websites, wie wir sie heute nutzen, brechen und den NutzerInnen mehr Freiheit und Autonomie bei der Nutzung und Verwaltung ihrer Daten und Kommunikationswege bieten.
Die Idee, dass Verteilung (Distribution) mehr Sicherheit bietet als zentralisierte Dienste, gewinnt nach sechzig Jahren wieder an Aktualität. Wir können es kaum erwarten, dass solche Dienste für die Allgemeinheit in gleicher Funktionalität zur Verfügung stehen, wie sie die zentralen Server der dominanten Unternehmen zur Zeit bieten.
